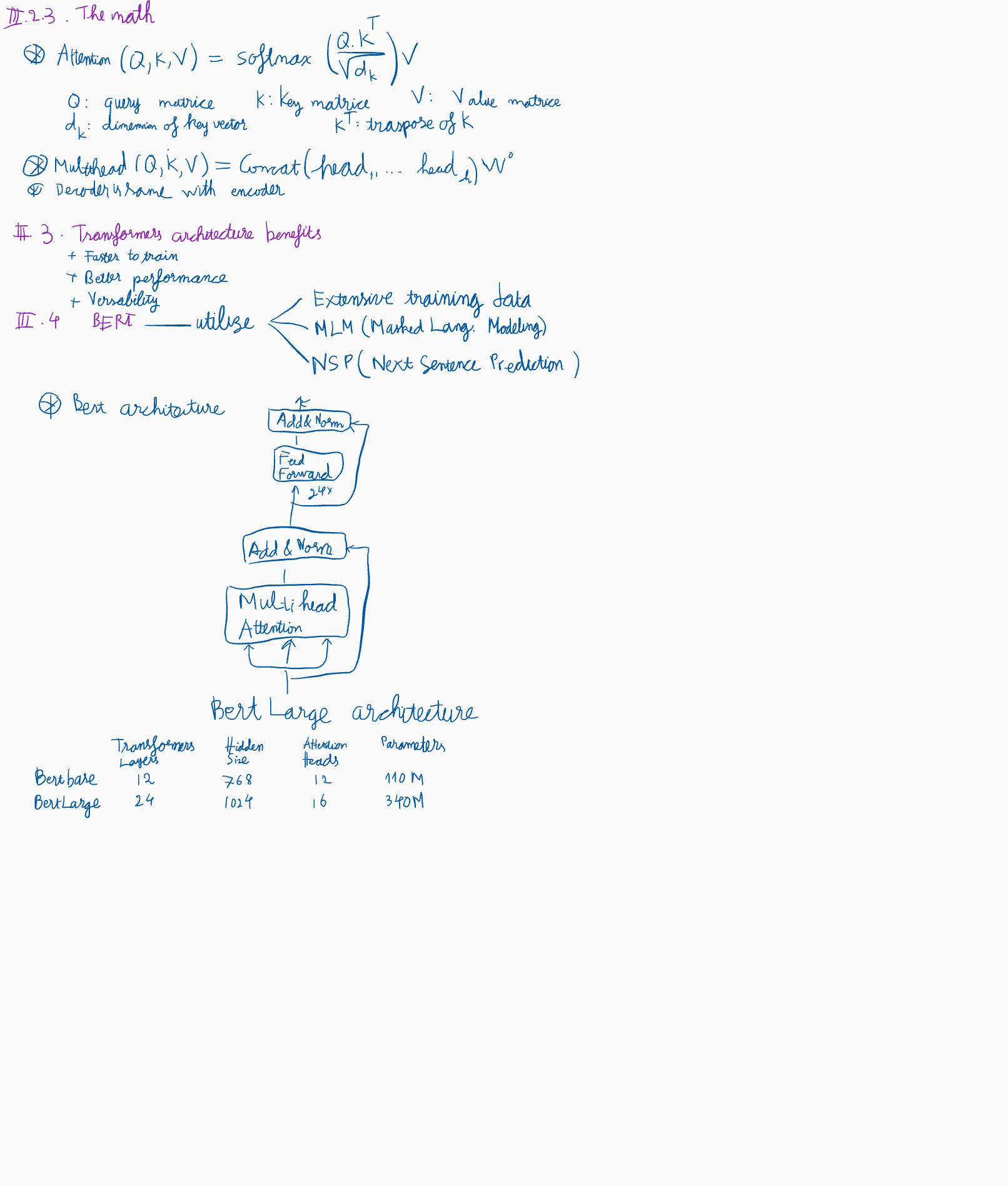

The self-attention mechanism works by computing attention weights between each input token and all other input tokens and using these weights to compute a weighted sum of the input token embeddings. The attention weights are computed using a softmax function applied to the dot product of a query vector, a key vector, and a scaling factor. The query vector is derived from the previous layer’s hidden representation, while the key and value vectors are derived from the input embeddings. The resulting weighted sum is fed into a multi-layer perceptron (MLP) to produce the next layer’s hidden representation.
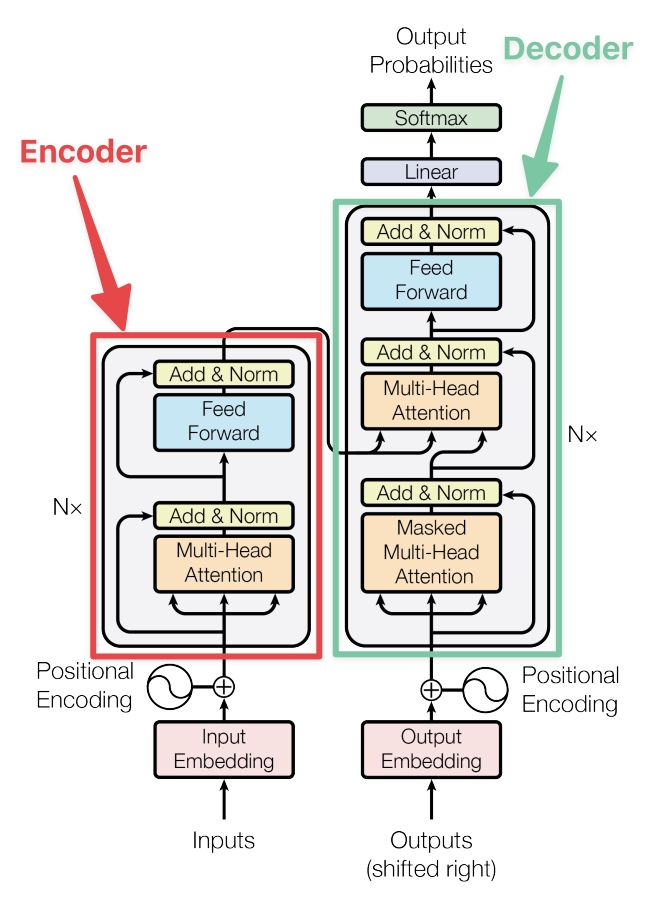
EncoderLayer(x) = LayerNorm(x + SelfAttention(x) + FeedForward(x))
III.2.2. Key, Value and Query

- Key: You can think of the key vectors as a set of reference points the model uses to decide which parts of the input sequence are important.
- Value: The value vectors are the actual information that the model associates with each key vector.
- Query: Query vectors are used to determine how much attention to give to each key-value pair.